

A brief overview of diffusion models and the architure that has lead to modern day implementations.
I’ll be using this a rough guide as I further explore each model in greater detail.
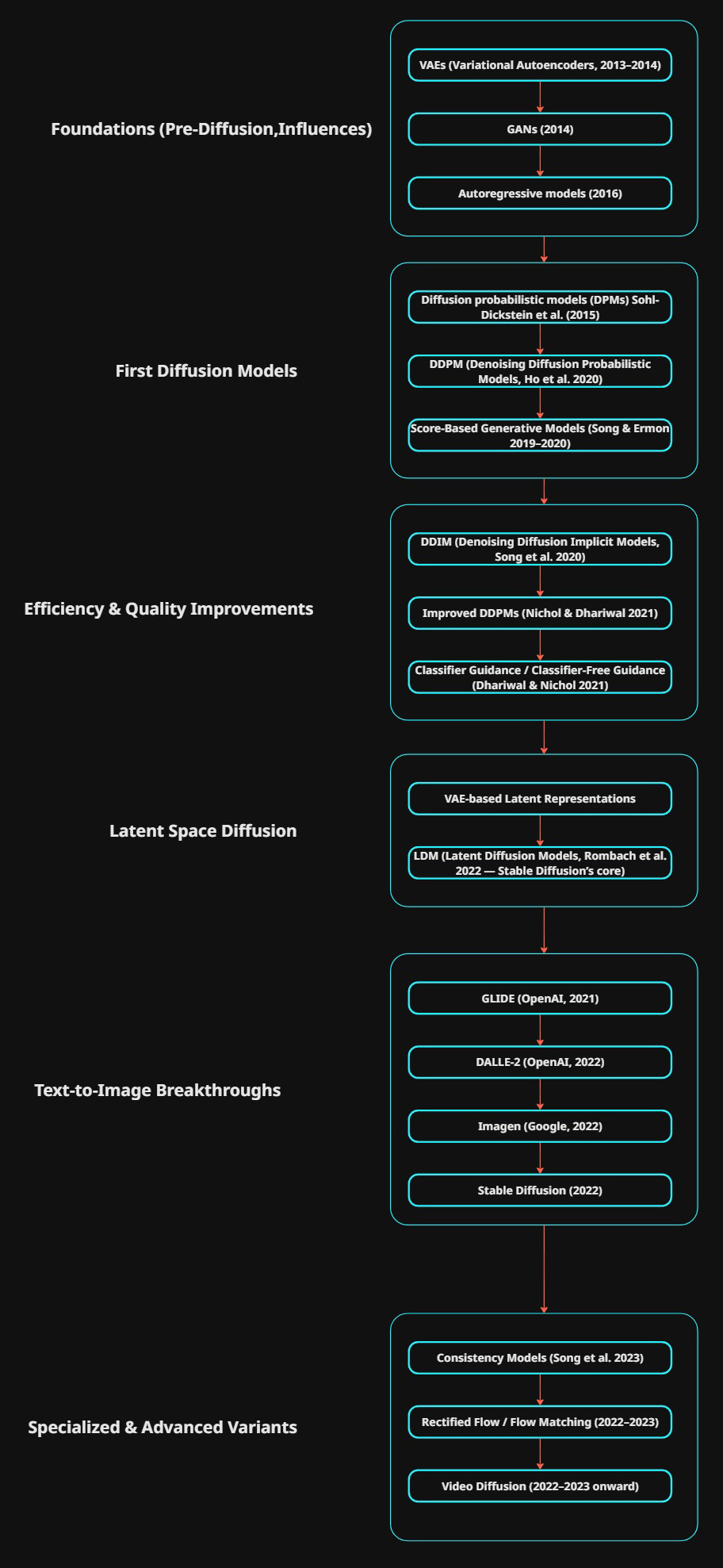
Foundations (Pre-Diffusion, Influences)
Before diffusion models, generative modeling was dominated by:
- VAEs (Variational Autoencoders, 2013–2014) → probabilistic latent-variable models with encoder–decoder structure. Key influence on later latent diffusion.
- GANs (2014) → direct adversarial training for images, not diffusion but often compared.
- Autoregressive models (e.g., PixelCNN 2016, PixelRNN 2016) → inspired sequential generation ideas later seen in diffusion.
First Diffusion Models
- Sohl-Dickstein et al. (2015) — Deep Unsupervised Learning using Nonequilibrium Thermodynamics
- First formulation of diffusion probabilistic models (DPMs).
- Forward process = gradual noise addition, reverse = denoising.
- DDPM (Denoising Diffusion Probabilistic Models, Ho et al. 2020)
- First widely adopted modern diffusion model.
- Uses a U-Net–like architecture.
- Key idea: reverse process parameterized by neural net.
- This is the “ImageNet/Gaussian noise baseline.”
- Score-Based Generative Models (Song & Ermon 2019–2020)
- Independently introduced score matching with stochastic differential equations.
- Equivalent to DDPM, but phrased in continuous time.
Efficiency & Quality Improvements
- DDIM (Denoising Diffusion Implicit Models, Song et al. 2020)
- Deterministic sampling version of DDPM.
- Much faster inference (fewer steps).
- Improved DDPMs (Nichol & Dhariwal 2021)
- Better noise schedules, architecture tweaks, guidance strategies.
- Classifier Guidance / Classifier-Free Guidance (Dhariwal & Nichol 2021)
- Conditioning trick to boost fidelity/controllability.
- Used in many modern text-to-image systems.
Latent Space Diffusion
- VAE-based Latent Representations
- VAE (2013) ideas are re-used here: instead of diffusing in pixel space, compress to latent first.
- LDM (Latent Diffusion Models, Rombach et al. 2022 — Stable Diffusion’s core)
- Diffusion happens in latent space learned by an autoencoder (usually a VAE).
- Enables much faster and memory-efficient generation.
- This is the foundation of Stable Diffusion.
Text-to-Image Breakthroughs
- GLIDE (OpenAI, 2021)
- Diffusion + text conditioning.
- Predecessor to DALL·E 2.
- DALLE-2 (OpenAI, 2022)
- Uses CLIP embeddings + diffusion decoder.
- Imagen (Google, 2022)
- Text-to-image with T5 embeddings.
- Large-scale high-quality results.
- Stable Diffusion (2022)
- Open-source implementation of LDM + text conditioning (via CLIP).
- Spawned the whole open ecosystem.
Specialized & Advanced Variants
- Consistency Models (Song et al. 2023)
- Train for one-step or few-step generation while maintaining diffusion quality.
- Rectified Flow / Flow Matching (2022–2023)
- Reformulate diffusion as ODE/flow problem.
- Faster, cleaner math, used in some next-gen models.
- Video Diffusion (2022–2023 onward)
- e.g., Imagen Video, Pika Labs, Runway.
- Extend LDMs into temporal dimensions.
Summary of Key Logical Lineage
- DDPM (2020) ← from original Sohl-Dickstein DPMs (2015).
- DDIM (2020) is a deterministic/speedup variant of DDPM.
- Improved DDPMs (2021) refine DDPM.
- Classifier-free guidance is an add-on, not a new model.
- LDM (2022) = DDPM in VAE latent space.
- Stable Diffusion (2022) = LDM + CLIP conditioning.
- GLIDE / DALLE-2 / Imagen = LDM/score-based diffusions + text conditioning.
- Consistency Models / Flow Matching = alternative formulations for efficiency.
- DDPM → DDIM → Improved DDPM → LDM → Stable Diffusion is the direct core lineage.
- Score-based models are parallel but mathematically equivalent.
- VAEs reappear as the backbone for LDMs.
- GANs/autoregressive were competitors, but diffusion superseded them.