

Note: This study is still in progress. Consider it a rough draft.
CLIP (Contrastive Language–Image Pretraining) is a joint embedding model that learns a shared semantic space between images and text.
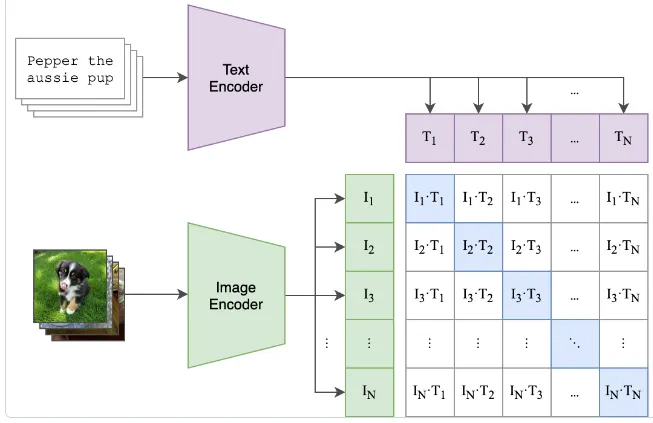
The model works with text-image pairs with each data type encoded with either the image encoder or text encoder respectively. Both encoders produce a vector embedding within the same vector-space.
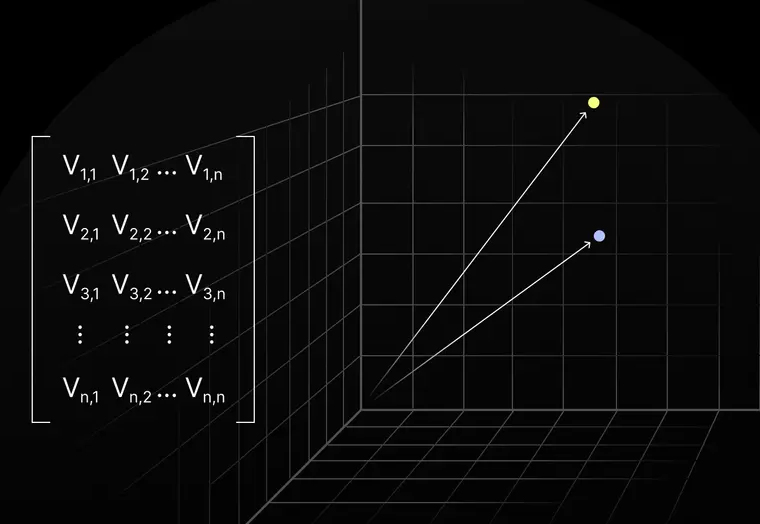
Its worth noting that the vector embeddings are of high dimensionality, for visualization they may be represented as 2 or 3 dimensions but in reality they are often of shape [1,512] which is a 512 dimension vector which is not suitable for visualization.
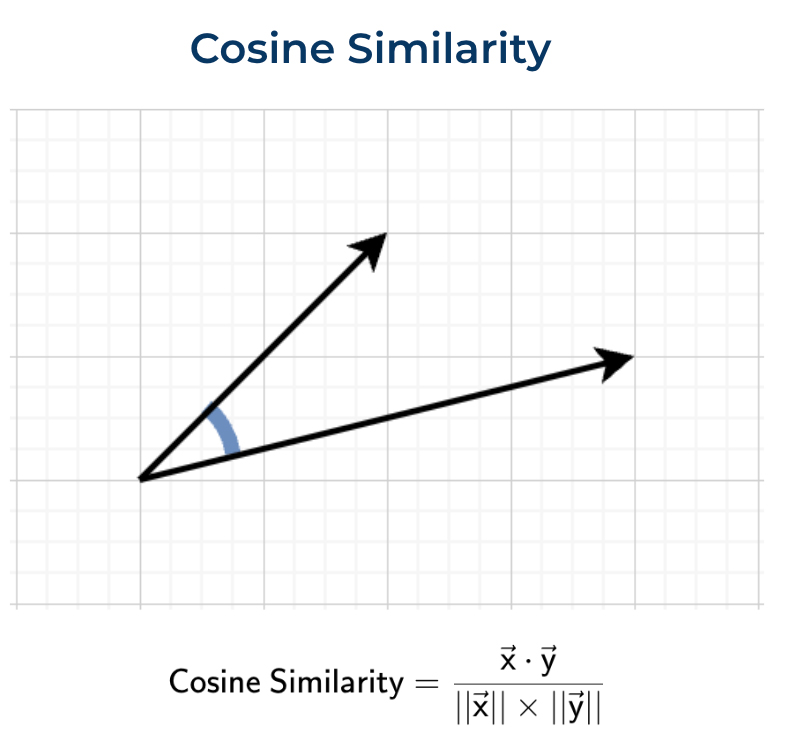
The two vectors are compared to each other using cosine similarity to measure how similar their directions are between the text embedding and the image embedding. Because these two embeddings are within the same pair, they represent the ground truth and optimization function is rewarded for pushing the two embeddings to be as close as possible to one another, relative to all other pairs within the current batch.
The cosine similarity is then used within the cross-entropy loss function in order to calculate the gradients that are used to adjust both encoders weights and biases during back propagation.
In addition to comparing the pair vector embeddings to each other, all the pairs within the same batch are also compared to all other pairs with that batch using cosine similarity, however because we are now comparing embeddings that don’t belong in the same pair, they are treated as contrastive and the optimizer is penalized for similarity and encourage to produce embeddings that are not similar in direction.
For each batch, every pair is encourage to have embeddings that point in a similar direction to each other, while pointing in dissimilar directions to all other pairs.
The embeddings are compared to opposing embedding types
- Text Embeddings -> Image Embeddings
- Image Embeddings -> Text Embeddings
CLIP conventionally is trained with huge batch sizes of around 30,000+ pairs. This provides a huge variety of directional similarities or dissimilarity to optimize for, batches by standard shuffle per epoch.
The training objective is to minimize the angle between the text and image embedding within each pair and to increase the angle between contrastive pairs as much as possible. Thus why its a contrastive model.
Meaning-Space
CLIP trains two encoders to map different modalities into a shared semantic vector space
- Image Encoder: learns which visual features correspond to linguistic concepts
- Text Encoder: learns which linguistic features correspond to visual concepts
This is achieved by training the encoders so that embeddings from matching image–text pairs are directionally aligned, which over many batches causes semantically related images and texts to occupy nearby regions (clusters) in the shared embedding space.
These clusters of semantically similar embeddings are an emergent behaviour from the gradual improvements from the encoder learning how to better encode embeddings relative to their inputs. Similar semantic embeddings result in grouping together over many iterations.
Training Outcome
As a result of both the encoders producing embeddings that are positionally clustered with similar semantic concepts, the space now has meaning.
- The image encoder can be used on its own to create meaningful embeddings based on input images. Each image embedding will now be semantically aligned with the linguistic meaning of that image and in the “neighbourhood” of similar semantic concepts.
- The text encoder can be used on its own to create meaningful embeddings. Each text embedding will now be semantically aligned with the visual meaning of that input text and in the “neighbourhood” of similar semantic concepts.
The high dimensional semantically aligned vector space forms a continuous manifold with no hard divisions or discreet components – This allow for zero-shot learning, interpolation and diffusion conditioning.
Continuous semantic manifold
- Continuous space (not discrete labels)
- Smooth (small moves = small semantic change)
- Shared across modalities
Zero-Shot generalization
- CLIP can respond predictably to unseen inputs as it only needs the semantic direction implied by the text
“a photo of a red ceramic teapot in the style of van gogh”
CLIP has likely never seen this exact phrase. But each component lies in a nearby region of the manifold.
the resulting embedding will still produce a valid point that is interpretable and meaningful.
Semantic interpolation
0.5 * (“cat”) + 0.5 * (“dog”) → “cat–dog hybrid”
- Directions interpolate meaningfully
- No sharp class boundaries exist
Compositionality
CLIP embeddings compose roughly linearly
“photo” + “oil painting”
“realistic” − “photo”
“style A” + “subject B”
- Meaning is encoded geometrically
- Not symbolically
Tokens Vs Pooled
When using the encoder for inference vs training the text embeddings are handled differently
When in training the whole sentence or wording is created into 1 vector embedding representing a single semantic direction in the vector space.
However when using the text encoder for inference, the text input is maintained as tokens.
For example:
Input text
A red dog with a top hatTraining
In training this whole sentence or group of words will be used as the text that pairs to a single image.
- 1) Text -> tokenized to 77 tokens
- 2) Tokens -> processed by a Transformer
- 3) The sequence is collapsed to ONE vector of dimension D (e.g. 512)
- 4) Only that one vector is used in the contrastive loss within training
The sentence is broken down into something like:
[token₁, token₂, token₃, … token₇₇]It include a special EOS (end-of-sentence) token
The transformer ( text encoder ) produces contextual embeddings for every token.
output : [77, D]
At this point “red”, “dog”, “hat” are separate vectors, Meaning is distributed across tokens.
Each token embedding can be thought of as a direction in semantic space.
These 77 tokens are then collapsed into a single embedding that represents all 77 semantic directions.
The pooled sentence embedding is not a simple sum of those directions, but a learned, weighted aggregation (via attention) that combines them into a single semantic direction representing the whole sentence.
This occurs via the special EOS token that attends to all other tokens, its the final embedding that becomes a learned function with all token embeddings.
Inference
Although CLIP training uses a pooled sentence embedding for the contrastive loss, the text encoder must internally preserve token-level semantic structure; as a result, individual token embeddings (e.g. “red”, “dog”, “hat”) retain meaningful, separable directions that can be used independently at inference time, even though training supervision was applied only at the pooled level.