

Note: This study is still in progress. Consider it a rough draft.
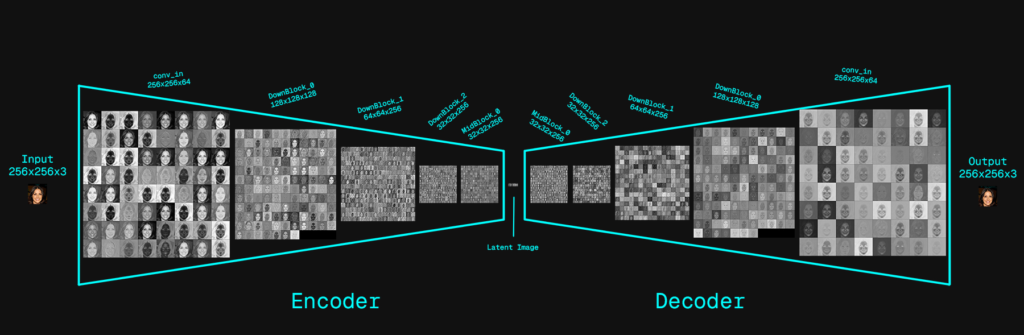
VAE Neural Network
This neural network is a Variational Autoencoder (VAE) built from two convolutional neural networks that are trained together as a single system. The encoder CNN takes an input image and progressively downsamples it through convolutional blocks, transforming pixel data into a compact latent representation. Rather than producing a single fixed latent tensor, the encoder predicts the parameters of a probability distribution—specifically a mean and a log-variance—for each latent channel. A stochastic latent sample is then drawn using the reparameterization trick, which introduces controlled randomness while preserving gradient flow during training. The decoder CNN mirrors the encoder in reverse: it takes the sampled latent tensor and progressively upsamples it through convolutional layers to reconstruct the original image. With the exception of the latent sampling step, all operations in both the encoder and decoder are standard CNN computations. The probabilistic bottleneck forces the model to learn a smooth, structured latent space, enabling robust reconstruction, interpolation, and generative capabilities rather than simple memorization.
Encoder
Input Image: 256×256×C(3)
- Level 1: 256×256×C(64)
- ResBlock
- ResBlock
- Downsample
- Level 2: 128×128×C(128)
- ResBlock
- ResBlock
- Downsample
- Level 3: 64×64×C(256)
- ResBlock
- ResBlock
- Downsample
- Level 4: 32×32×C(256)
- ResBlock
- ResBlock
- → Output Latent: 32×32×C(256)
Encoder
Input Latent: 32×32×C(256)
- Level 4: 32×32×C(256)
- ResBlock
- ResBlock
- Upsample
- Level 3: 64×64×C(256)
- ResBlock
- ResBlock
- Upsample
- Level 2: 128×128×C(128)
- ResBlock
- ResBlock
- Upsample
- Level 1: 256×256×C(64)
- ResBlock
- ResBlock
- → Output Image: 256×256×C(3)
Lets dive into the VAE model code. (vae.py)
##################### vae.py: VAE()
import torch
import torch.nn as nn
from models.blocks_simple import DownBlock, MidBlock, UpBlock
class VAE(nn.Module):
def __init__(self):
super().__init__()
# Latent Dimension
self.z_channels = 4- DownBlock, MidBlock, UpBlock are custom neural network blocks that will dive into later.
- The VAE model class inherits nn.Module to turn the class into a trainable neural network, it ensure the following:
- Automatic parameter registration: Any layer you assign as an attribute is automatically registered into model.parameters()
- Recursive module tracking: Allowing for nested nn.Modules
- The forward() contract: z = model(x) -> call self.forward(x)
- Autograd integration (gradient flow): Integrates your computation graph with autograd.
- Model state management: Saving / Loading state & Device managemnt.
- super().init() called to initialize nn.Module
- A latent dimension of 4 is used for the channels of the export latent (z)
Encoder Modules: __init__ vae.py
Below is the architecture for the encoder which is established within __init__(). Lets go through each module individually.
##################### vae.py: __init__() cont.
##################### Encoder ######################
# Input Projection
self.encoder_conv_in = nn.Conv2d(
in_channels = 3,
out_channels = 64,
kernel_size = 3,
padding = (1, 1)
)
# Encoder block 0
self.encoder_layers_0 = DownBlock(
in_channels = 64,
out_channels = 128,
down_sample = True,
num_layers = 2,
norm_channels = 32
)
# Encoder block 1
self.encoder_layers_1 = DownBlock(
in_channels = 128,
out_channels = 256,
down_sample = True,
num_layers = 2,
norm_channels = 32
)
# Encoder block 2
self.encoder_layers_2 = DownBlock(
in_channels = 256,
out_channels = 256,
down_sample = True,
num_layers = 2,
norm_channels = 32
)
# Bottleneck
self.encoder_mids_0 = MidBlock(
in_channels = 256,
out_channels = 256,
num_heads = 4,
num_layers = 2,
norm_channels = 32
)
# Output normalization
self.encoder_norm_out = nn.GroupNorm(
num_groups = 32,
num_channels = 256
)
# Latent parameter projection
self.encoder_conv_out = nn.Conv2d(
in_channels = 256,
out_channels = 2 * self.z_channels,
kernel_size = 3,
padding = 1
)
# Latent reparameterization projection
# Latent Dimension is 2*Latent because we are predicting mean & variance
self.pre_quant_conv = nn.Conv2d(
in_channels = 2 * self.z_channels,
out_channels = 2 * self.z_channels,
kernel_size = 1
)
####################################################Input Projection
Lets focus on the input projection from code block 2
##################### vae.py: __init__()
# Input Projection
self.encoder_conv_in = nn.Conv2d(
in_channels = 3,
out_channels = 64,
kernel_size = 3,
padding = (1, 1)
)- 2D Convolution layer learns:
- Edge detectors (horizontal, vertical, diagonal)
- Color contrasts
- Simple textures
- Frequency-oriented filters
- kernal = 3×3 convolution kernel, this filter is what is being trained.
- 1 pixel padding border – this ensures the original spatial size is preserved during the 3×3 convolution.
- Converts RGB input (C=3) into 64 feature maps.
- At the end of this layer the shape is:
- 256x256x64 (64 channels which are the feature maps)
Encoder DownBlocks Modules
The down blocks are modules that contain multiple layers and logic to handle convolution layers as well as down sampling. Acting as a reusable block of CNN. Below is how these down blocks are being initialized in the VAE __init__ method.
##################### vae.py: __init__()
# Encoder block 0
self.encoder_layers_0 = DownBlock(
in_channels = 64,
out_channels = 128,
down_sample = True,
num_layers = 2,
norm_channels = 32
)
# Encoder block 1
self.encoder_layers_1 = DownBlock(
in_channels = 128,
out_channels = 256,
down_sample = True,
num_layers = 2,
norm_channels = 32
)
# Encoder block 2
self.encoder_layers_2 = DownBlock(
in_channels = 256,
out_channels = 256,
down_sample = True,
num_layers = 2,
norm_channels = 32
)
DownBlock Module
Lets jump into blocks.py to understand this module.
The module has two functions:
- Feature extraction: learns patterns at this resolution
- Compression:
- down samples so deeper parts see larger context (bigger receptive field)
- reduces compute -> (B,C,H,W)->(B,C,H/2,W/2)
This module is made up of ResNet-style residual block and a down sampling layer
- Residual block:
- resnet_conv_first: (Norm → Activation → Conv)
- resnet_conv_second: (Norm → Activation → Conv)
- residual_input_conv: (1×1 Conv on skip path, if needed)
- Down sampling:
- down_sample_conv
The residual block gets created twice and stacked as num_layers = 2, thus with the configuration that is being used this block is comprised of 2 residual blocks and a down sampling layer at the end.
- Residual block #1
- Residual block #2
- Down sampling
ResNet (residual Network): is a type of neural network architecture designed to make very deep networks trainable.
As networks get deeper, they often suffer from:
- Vanishing gradients
- Degradation (adding more layers makes performance worse, not better)
The key idea: residual learning – Instead of forcing layers to learn a full transformation
$$H(x)$$
ResNet makes them learn a residual which is the delta between the input and output:
$$F(x)=H(x)-x$$
So the block outputs: Which adds the delta onto the input to get the full transform.
$$y=F(x)+x$$
- Gradients flow easily through skip connections
- If a block is not useful, it can learn F(x) ≈ 0, behaving like an identity
- Deep networks become easier to optimize
Lets break down this module to understand what is happening. Below is the class constructor along with the initialization method that constructs the layers and operations within this block.
##################### blocks.py: DownBlock __init__()
class DownBlock(nn.Module):
def __init__(self, in_channels, out_channels,
down_sample, num_layers, norm_channels):
super().__init__()
self.num_layers = num_layers
self.down_sample = down_sample
self.resnet_conv_first = nn.ModuleList(
[
nn.Sequential(
nn.GroupNorm(norm_channels, in_channels if i == 0 else out_channels),
nn.SiLU(),
nn.Conv2d(in_channels if i == 0 else out_channels, out_channels,
kernel_size=3, stride=1, padding=1),
)
for i in range(num_layers)
]
)
self.resnet_conv_second = nn.ModuleList(
[
nn.Sequential(
nn.GroupNorm(norm_channels, out_channels),
nn.SiLU(),
nn.Conv2d(out_channels, out_channels,
kernel_size=3, stride=1, padding=1),
)
for _ in range(num_layers)
]
)
self.residual_input_conv = nn.ModuleList(
[
nn.Conv2d(in_channels if i == 0 else out_channels, out_channels, kernel_size=1)
for i in range(num_layers)
]
)
self.down_sample_conv = nn.Conv2d(out_channels, out_channels,
4, 2, 1) if self.down_sample else nn.Identity()- Initialization arguments:
- in_channels: how many channels come in
- out_channels: how many channels it should output
- down_sample: whether to halve resolution at the end
- num_layers: how many “mini-residual blocks” to stack inside
- norm_channels: number of normalization groups for GroupNorm (common: 32)
As an exmaple, assuming the following in_channels = 64, out_cahnnels = 128 & down_sample = True
| Input | (B,64,256,256) |
| Residual mini-block 1 | (B,128,256,256) |
| Residual mini-block 2 | (B,128,256,256) |
| Down sample | (B,128,128,128) |
GroupNorm
nn.GroupNorm(norm_channels, num_channels)
Normalization layers try to keep activations in a stable range so training is easier.
Essentially this layer takes the number of channels and divides it into groups. Each groups channels is normalized relative to the group its in. norm_channels specificize how many groups to put the channels in.
example:
- 128 channels ÷ 32 groups = 4 channels per group
- Each group is normalized independently
- For each group, GroupNorm computes:
- mean over (group channels × H × W)
- std over (group channels × H × W)
resnet_conv_first
Lets take a look resnet_conv_first which is the first half of the residual convolution block.
##################### blocks.py: DownBlock __init__()
self.resnet_conv_first = nn.ModuleList(
[
nn.Sequential(
nn.GroupNorm(norm_channels, in_channels if i == 0 else out_channels),
nn.SiLU(),
nn.Conv2d(in_channels if i == 0 else out_channels, out_channels,
kernel_size=3, stride=1, padding=1),
)
for i in range(num_layers)
]
)The logic creates num_layers number of sub-layers. Each sub-layer is: GroupNorm -> SiLU -> Conv2d (3×3), with a small adjustment to inputs after the first iteration.
When i == 0: GroupNorm & Conv2d use in_channels as inputs, but once this first iteration has occured and i != 0, then out_channels is used as inputs to these two layers instead.
This is because the Conv2d converts the shape of the tensor from (B,in_channels,W,H) -> (B,out_channels,W,H) , so any additional layers in this sub-block need to switch to out_channels to account for the new shape of the tensor after the first iteration.
- nn.ModuleList([…]): A torch container for modules, needed to ensure torch reliably see’s the layers as part of the model
- nn.Sequential(…): acts as a pipeline to execute the layers in order and daisy chains the outputs from the previous layer in the input of the next.
nn.ModuleList(
[ nn.Sequential(...) for i in range(num_layers) ]
)- list comprehension: for i in range(num_layers): This builds num_layers number of separate Sequential modules.
- If num_layers = 2, you get:
- self.resnet_conv_first[0]
- self.resnet_conv_first[1]
- If num_layers = 2, you get:
As for the layers with in the nn.Sequential pipeline:
##################### blocks.py: DownBlock __init__()
nn.Sequential(
nn.GroupNorm(norm_channels, in_channels if i == 0 else out_channels),
nn.SiLU(),
nn.Conv2d(in_channels if i == 0 else out_channels, out_channels,
kernel_size=3, stride=1, padding=1),
)- GroupNorm: Groups the channels then normalizes each group independently, this is done for stability.
- SiLU: Sigmoid Linear Unit (Swish) activation function. Standard choice for VAEs, UNets. Provides smooth gradients and better gradient flow in deep networks.
- Conv2d: The trainable aspect of this block, the 3x3xC filter learns to extract further meaningful features from the original input tensor and generate additional feature maps (channels) -> (B,64,W,H) -> (B,128,W,H)
- If this block is run multiple times, as it is with this implementation. This goes from converting input(B,64,W,H) -> output(B,128,W,H) to input(B,128,W,H) -> output(B,128,W,H). The second iteration no longer generates additional channels and instead learns to refine the features maps further. The first and second iteration have independent weights so each iterations Conv2d 3x3xC filter is trained independently to improve the feature maps being created.
resnet_conv_SECOND
The resnet_conv_second sub-block is more or less the same architecture as the resnet_conv_first, It is the second half of the residual convolution block. The only different of this sub-block since it is executed after resnet_conv_first and as a result the tensor has already been transformed into having out_channels number of channels. So we do not to consider in_channels at all in this sub-block.
##################### blocks.py: DownBlock __init__()
self.resnet_conv_second = nn.ModuleList(
[
nn.Sequential(
nn.GroupNorm(norm_channels, out_channels),
nn.SiLU(),
nn.Conv2d(out_channels, out_channels,
kernel_size=3, stride=1, padding=1),
)
for _ in range(num_layers)
]
)- The reason we need this sub-block instead of simply using the first sub-block with num_layers = 4. Is because we need to add the skip path after exactly 2 convolutional layers and this will become apparent when we get into the forward() method.
residual_input_conv
This can be referred to as a skip path, its the last sub-component to make up the convolutional residual block. It is comprised of a single Conv2D layer which uses a 1x1xC convolutional filter .
The main goal of the skip path is to project the original input tensor into the block’s channel space (out_channels) while preserving its information as directly as possible, so it can be added back to the residual transformed output.
##################### blocks.py: DownBlock __init__()
self.residual_input_conv = nn.ModuleList(
[
nn.Conv2d(in_channels if i == 0 else out_channels, out_channels, kernel_size=1)
for i in range(num_layers)
]
)- 1x1xC Convolutional filter , essentially its a 1 pixel filter that mixes the channels together when projecting to the desired number of channels.
- This convolution is trained to be as close to identity as possible as the 1×1 kernel will not mix spatial information or distort structure.
- When i != 0 Conv2d is still needed as this convolutional layer not only learns how to create an identity of the original input projected into “block channel space” i.e convert from in_channesl -> out_channels. This layer also learns how how much of each channel to mix the identity tensor with the residual delta that is being calculated by the previous two convolutional sub-blocks, So it learns the balance per block when num_layers > 1
down_sample_conv
This last layer of the DownBlock module is not part of the residual convolution block. This layer is used to down sample the tensor from (B,C,H,W)->(B,C,H/2,W/2) , granted that self.down_sample == True. If down_sample != True a identity layer is substituted instead, Which simply returns the input.
##################### blocks.py: DownBlock __init__()
self.down_sample_conv = nn.Conv2d(out_channels, out_channels,
4, 2, 1) if self.down_sample else nn.Identity()Convo2d is trainable layer, so this is a learned down sampling operation (not just average/max). This can preserve important structure better and is standard in VAEs / diffusion U-Nets.
- kernel_size = 4
- stride = 2
- padding = 1
The above configuration is a common “clean halving” setup.
- (N) = input size (height or width)
- (K) = kernel size
- (S) = stride
- (P) = padding
$$out = bigg[frac{N+2P-K}{S}bigg]+1$$
$$out = bigg[frac{256+2(1)-4}{2}bigg]+1$$
if (N) = even (which it usually is in CNNs):
$$out = frac{N}{2}$$
DownBlock forward()
Ok, now that we have gone over the constructure method of this DownBlock module, We can get into the execution method forward()
##################### blocks.py: DownBlock forward()
def forward(self, x):
out = x
for i in range(self.num_layers):
# Resnet block of Unet
resnet_input = out
out = self.resnet_conv_first[i](out)
out = self.resnet_conv_second[i](out)
out = out + self.residual_input_conv[i](resnet_input)
# Downsample
out = self.down_sample_conv(out)
return outResnet Block
The main convolutions of this block occurs in a standard ResNet-style residual block which is:
$$y=F(x)+S(x)$$
where:
- (x) = Original input used for the skip path(resnet_input)
- (F(x)) = Main path, two stacked convolutional transforms
- GroupNorm → SiLU → Conv(3×3)
- (S(x)) = skip path (1×1 projection), that gets added to the main path
This is the standard architecture for the a ResNet style block:
- There is a main path (F(x))
- There is a skip path that bypasses it
- The output is the sum of the two
We set num_layers = 2, which stacks two of these residual blocks together.
- Block Loop:
num_layers is iterated over as two convolutional residual blocks have been created in initialization. Since we are using 2 residual blocks we run the following twice:resnet_input = out- We make a copy of the input, so we have the original which will be added along with the residual transforms learned in the convolution sub-blocks.
out = self.resnet_conv_first[i](out)- The first convolution sub-block in the main path
out = self.resnet_conv_second[i](out)- The second convolution sub-block in the main path
out = out + self.residual_input_conv[i](resnet_input)- Here the main path and skip path get added together. The skip path runs through the resudual_input_conv to both project the original tensor into the same channel dimensions as the main path and also learn the optimal weighting of each channel to add add with the residual transforms learned in the main path.
Two Convolutions
This is important as 1 convolution is too weak, 2 is expressive enough and 3 creates a bottleneck block. 2 is the standard ResNet block architecture.
$$F(x) = g_2(g_1(x))$$
Once the two residual blocks have been executed, the last step is the down sampling and completes the logic breakdown of what occurs in the DownBlock.
Encoder Modules: __init__ vae.py cont.
Back in the VAE model module, where the encoder stages are being defined in the constructer. 3 DownBlocks are being defined, These DownBlocks are consecutively deepening the dimensionality of the tensor as we expand from 64 channels -> 256, while halving the spatial resolution at each layer, reducing the spatial dimensionality to 1/64th of the original image, each pixel gains more information as the number of channels increasing from 64 to 256.
Each DownBlock trades spatial detail for semantic abstraction, turning local visual primitives into stable, high-level representations that are suitable for compression into a smooth latent space.
##################### vae.py: __init__() Cont.
# Encoder block 0
self.encoder_layers_0 = DownBlock(
in_channels = 64,
out_channels = 128,
down_sample = True,
num_layers = 2,
norm_channels = 32
)
# Encoder block 1
self.encoder_layers_1 = DownBlock(
in_channels = 128,
out_channels = 256,
down_sample = True,
num_layers = 2,
norm_channels = 32
)
# Encoder block 2
self.encoder_layers_2 = DownBlock(
in_channels = 256,
out_channels = 256,
down_sample = True,
num_layers = 2,
norm_channels = 32
)
Encoder MidBlock Module (bottleneck)
The Mid block module is very similar to to the DownBlock with 2 main differences:
- MidBlock does not down sample: It stays at the “bottleneck” resolution
- MidBlock includes global self-attention
##################### vae.py: __init__() Cont.
self.encoder_mids_0 = MidBlock(
in_channels = 256,
out_channels = 256,
num_heads = 4,
num_layers = 2,
norm_channels = 32
)Lets jump back into blocks.py and break down this module to understand what is happening. Below is the class constructor along and initialization method that constructs the layers and operations within the MidBlock.
##################### blocks.py: MidBlock __init__()
class MidBlock(nn.Module):
def __init__(self, in_channels, out_channels, num_heads, num_layers, norm_channels):
super().__init__()
self.num_layers = num_layers
self.resnet_conv_first = nn.ModuleList(
[
nn.Sequential(
nn.GroupNorm(norm_channels, in_channels if i == 0 else out_channels),
nn.SiLU(),
nn.Conv2d(in_channels if i == 0 else out_channels, out_channels, kernel_size=3, stride=1,
padding=1),
)
for i in range(num_layers + 1)
]
)
self.resnet_conv_second = nn.ModuleList(
[
nn.Sequential(
nn.GroupNorm(norm_channels, out_channels),
nn.SiLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1),
)
for _ in range(num_layers + 1)
]
)
self.attention_norms = nn.ModuleList(
[nn.GroupNorm(norm_channels, out_channels)
for _ in range(num_layers)]
)
self.attentions = nn.ModuleList(
[nn.MultiheadAttention(out_channels, num_heads, batch_first=True)
for _ in range(num_layers)]
)
self.residual_input_conv = nn.ModuleList(
[
nn.Conv2d(in_channels if i == 0 else out_channels, out_channels, kernel_size=1)
for i in range(num_layers + 1)
]
)
- Initialization arguments:
- in_channels/out_channels: channel sizes in/out of this block
- num_heads: attention heads for multihead attention
- num_layers: how many attention +residual blocks to run
- norm_channels: number of groups in GroupNorm (often 32)
ResNet Residual Block
resnet_conv_first, resnet_conv_second & residual_input_conv are the same three sub-modules that makes up a residual network block. All three work in the same way as we have seen in the DownBlock with the exception of the num_layers loop, which creates 1 extra block than what is specified , with:
- for i in range(num_layers + 1)
This will become apparent in the forward() method, as the first block is reserved as a precursor prior to iterating on the Attention + Residual blocks that are specified with num_layers.
Attention
Attention is used in the bottleneck as the spatial resolution is small, so its efficient to do so at this stage. With num_layers = 2, two bocks will be created for attention, along with the residual blocks previously discussed.
##################### blocks.py: MidBlock __init__()
self.attention_norms = nn.ModuleList(
[nn.GroupNorm(norm_channels, out_channels)
for _ in range(num_layers)]
)
self.attentions = nn.ModuleList(
[nn.MultiheadAttention(out_channels, num_heads, batch_first=True)
for _ in range(num_layers)]
)- One GroupNorm per attention layer:Attention is sensitive to activation scale; normalizing before attention makes training stable.
- MultiheadAttention:
- embed_dim = out_channels (feature dimension)
- num_heads = num_heads (split channels into heads)
- batch_first=True → expects (B, seq_len, embed_dim)
In our residual convolution blocks we use a 3x3xC filters for our convolutions to extract out feature maps into each channel. Attention lets every spatial position interact with every other—great at the bottleneck where H×W is small.
This is the big difference: MidBlock has global mixing; DownBlock is purely local conv + downsample.
Multi Head Attention, essentially splits the number of channels (C=256) into the number of heads (num_heads=4). This gives each head a dim of 64.
Each pixel or spatial position is attention token, Each attention token represents one fixed spatial position, and its vector components come from different channels at that same position \(Q_i \in R^{ \ 64} \) where i represent each pixels position. every spatial token is dot-producted with every other spatial token (per head) to compute global relevance weights. Attention lets each spatial position decide which other spatial positions are relevant, and then incorporate information from them.
Each head might focus on different semantic features.
Lets compare attention to convolutions. Both operate on the same features maps but they learn fundamentally different kids of structure.
| Aspect | Convolution | Self-Attention |
|---|---|---|
| Receptive field | Local | Global |
| Weights | Fixed spatial kernel | Learned similarity |
| Adaptivity | Static | Content-dependent |
| Local detail | Excellent | Weak |
| Global structure | Poor alone | Excellent |
| Learned | edges → parts → textures → local semantics | symmetry across the image → repeated structures → object-level coherence → global layout |
| Position | high-resolution stages | bottleneck |
Convolutions learn what local patterns look like; attention learns which patterns across the image should influence each other. Both are needed and they compliment each other in creating coherent images.
MidBlock forward()
##################### blocks.py: MidBlock forward()
def forward(self, x):
out = x
# First resnet block
resnet_input = out
out = self.resnet_conv_first[0](out)
out = self.resnet_conv_second[0](out)
out = out + self.residual_input_conv[0](resnet_input)
for i in range(self.num_layers):
# Attention Block
batch_size, channels, h, w = out.shape
in_attn = out.reshape(batch_size, channels, h * w)
in_attn = self.attention_norms[i](in_attn)
in_attn = in_attn.transpose(1, 2)
out_attn, _ = self.attentions[i](in_attn, in_attn, in_attn)
out_attn = out_attn.transpose(1, 2).reshape(batch_size, channels, h, w)
out = out + out_attn
# Resnet Block
resnet_input = out
out = self.resnet_conv_first[i + 1](out)
out = self.resnet_conv_second[i + 1](out)
out = out + self.residual_input_conv[i + 1](resnet_input)
return outThe forward method for this block applies some of the logic that we have seen in the DownBlock, namely the Midblock incorporates the ResNet style residual convolution blocks.
- DownBlock:
num_layers loop:- ResNet-style residual blocks
- (GroupNorm → SiLU → Conv3×3)
- (GroupNorm → SiLU → Conv3×3)
- 1×1 projection on the skip path
- Down sampling convolution at the end (stride 2)
- ResNet-style residual blocks
However the MidBlock does not structure itself in the same way as the DownBlock , nor does it incorporate down sampling convolution layers. Instead it initially executes a ResNet-style residual block, then loops over num_layers with self-attention block + ResNet-style residual block.
- MidBlock:
- ResNet-style residual blocks
- (GroupNorm → SiLU → Conv3×3)
- (GroupNorm → SiLU → Conv3×3)
- 1×1 projection on the skip path
- num_layers loop:
- Self-attention over spatial tokens
- ResNet-style residual blocks
- (GroupNorm → SiLU → Conv3×3)
- (GroupNorm → SiLU → Conv3×3)
- 1×1 projection on the skip path
The initial ResNet Block is why we used the “num_layers + 1” when initializing the ResNet blocks in the __init__(). Index [0] is reserved for the initial ResNet block needed prior to the loop of num_layers number of blocks.
Lets discuss the intuition behind why its structured this way before jumping into the attention block details, the ResNet blocks have been previously covered so we will not be going into it again here.
MidBlock:
- Residual Block [0]:
- At the end of the last DownBlock is a down sample convolution layer, this ResNet applies the first residual refinement at the bottleneck resolution. this ensures the feature vectors are not noisy ,poorly normalized or weakly expressive after the last down sample. Overall this refines the local features to ensure the self-attention has clean data to work with.
- Self Attention N (num_layers):
- Global context is used to encode layout & context and aggregate information from all spatial locations
- Residual Block N ([i] + 1) :
- The second ResNet block re-applies convolutional inductive bias
- sharpens local structure
- removes artifacts introduced by global mixing
- smoothing/refining details
Lets jump into the attention + ResNet block(s) loop in the forward()
##################### blocks.py: MidBlock forward()
for i in range(self.num_layers):
# Attention Block
batch_size, channels, h, w = out.shape
in_attn = out.reshape(batch_size, channels, h * w)
in_attn = self.attention_norms[i](in_attn)
in_attn = in_attn.transpose(1, 2)
out_attn, _ = self.attentions[i](in_attn, in_attn, in_attn)
out_attn = out_attn.transpose(1, 2).reshape(batch_size, channels, h, w)
out = out + out_attn
# Resnet Block
resnet_input = out
out = self.resnet_conv_first[i + 1](out)
out = self.resnet_conv_second[i + 1](out)
out = out + self.residual_input_conv[i + 1](resnet_input)- Spatial Tokens:
batch_size, channels, h, w = out.shapein_attn = out.reshape(batch_size, channels, h * w)- from (B,C,W,H) -> (B,C,HW)
This converts the feature map format into HW spatial tokens of C-dimensions. This is the what self-attention will be using to compare to globally to every pixel location using the channels that have been grouped into the current head.
- attention_norms: Attention uses dot-products and normalization makes this stable and learnable.
- in_attn.transpose(1, 2): when batch_first=True on MultiheadAttention(), this formats it correctly so seq_len = HQ and embed_dim = C.
- (B,C,HW) -> (B,HW,C)
- out_attn, _ = self.attentions[i](in_attn, in_attn, in_attn): Self-Attention:
- queries, keys, values all come from the same sequence
- So each spatial position mixes in information from all other positions (global context).
- out_attn = out_attn.transpose(1, 2).reshape(batch_size, channels, h, w)
- Converts attention back into feature maps (image grid)
- (B,HW,C) -> transpose -> (B,C,HW) -> reshape -> (B,C,H,W)
- out = out + out_attn: Residual add for attention
After the attention block has executed, the last ResNet convolutional block runs. As mentioned we do not need to go into the detail here as it should be familiar by now.
Encoder Modules: __init__ vae.py cont.
lets jump back into the last layers that need setting up for the encoder sub-model. This last three layers are what will be needed to convert the feature maps into latent space.
##################### vae.py: __init__() Cont.
self.encoder_norm_out = nn.GroupNorm(
num_groups = 32,
num_channels = 256
)
self.encoder_conv_out = nn.Conv2d(
in_channels = 256,
out_channels = 2 * self.z_channels,
kernel_size = 3,
padding = 1
)
# Latent Dimension is 2*Latent because we are predicting mean & variance
self.pre_quant_conv = nn.Conv2d(
in_channels = 2 * self.z_channels,
out_channels = 2 * self.z_channels,
kernel_size = 1
)- encoder_norm_out: makes scale consistent / prevents the next conv from having to handle wildly varying activations
- encoder_conv_out: A 3×3 convolution that maps from 256 feature channels to ⋅z_channels
- pre_quant_conv:A 1×1 convolution operating on the 2z-channel tensor
- A 1×1 conv here acts like a learned linear mixer across the channels of [μ,logσ2].
def encode(self, x):
out = self.encoder_conv_in(x)
out = self.encoder_layers_0(out)
out = self.encoder_layers_1(out)
out = self.encoder_layers_2(out)
out = self.encoder_mids_0(out)
out = self.encoder_norm_out(out)
out = nn.SiLU()(out)
out = self.encoder_conv_out(out)
out = self.pre_quant_conv(out)
mean, logvar = torch.chunk(out, 2, dim=1)
std = torch.exp(0.5 * logvar)
sample = mean + std * torch.randn(mean.shape).to(device=x.device)
return sample, out